
What is the simplest algebraic structure lurking inside a table of data? If you look at a multiplication table—say the operations of a finite group—the bare numbers look like any other array of symbols. Yet beneath the surface, a single property holds the whole thing together: associativity. The identity (a · b) · c must equal a · (b · c) for every triple of entries. It is a rule so fundamental that the moment it fails, the table ceases to describe a group. The question that Dongsung Huh, Lior Horesh, and Halyun Jeong have now answered is whether a purely continuous, differentiable measure can feel that rule—and feel it so exactly that it can tell you, with mathematical certainty, whether the hidden algebraic structure is a group at all. Their work, appearing in a preprint (arXiv:2511.23152), transforms a combinatorial puzzle into a problem of landscape analysis, proving that a carefully sculpted loss function attains its absolute minimum if and only if the data table is isotopic to a group, and the minimizer is nothing less than the regular representation of that group. This is not an algorithm for messy real‑world data; it is an existence proof that the discrete world of algebra can be touched by the smooth machinery of gradient descent.
Let us step back. In classical machine learning, structure discovery often begins with matrix completion: you are handed a table with missing entries and you try to fill the gaps by assuming the whole thing is low‑rank. In algebra, the analogue is Cayley‑table completion. You have a partially filled table of binary operations—the multiplication table of a candidate group—and the missing entries must be guessed so that the completed table is associative. The trouble is that associativity is a discrete, non‑local constraint; it involves every triple of rows and columns simultaneously. It is like trying to rebuild a shattered symphony from stray notes, knowing only that harmony was there once. Combinatorial search can test candidate completions, but the sheer number explodes with table size. What if, instead of combing through possibilities, you could simply let a gradient‑based optimiser slide down a loss function whose low‑lying valleys naturally select the associative tables?
The idea was floated a year ago by Xie and collaborators (arXiv:2402.02681) in a paper that introduced HyperCube, an operator‑valued tensor factorization. Think of it as a kind of neural net for algebraic structures: each element of the table is assigned a parameterised matrix, and a custom objective function pushes those matrices to behave like a group’s multiplication table. The early results were promising—the method learned the right group tables from fully observed examples—but the optimisation landscape remained a black box. No one knew whether the loss had spurious local minima, or whether a genuine group structure always sat at its global bottom. The notion that a differentiable measure could exactly characterise discrete algebra was a lovely provocation; it lacked the proof that would elevate it from an empirical trick to a theoretical tool.
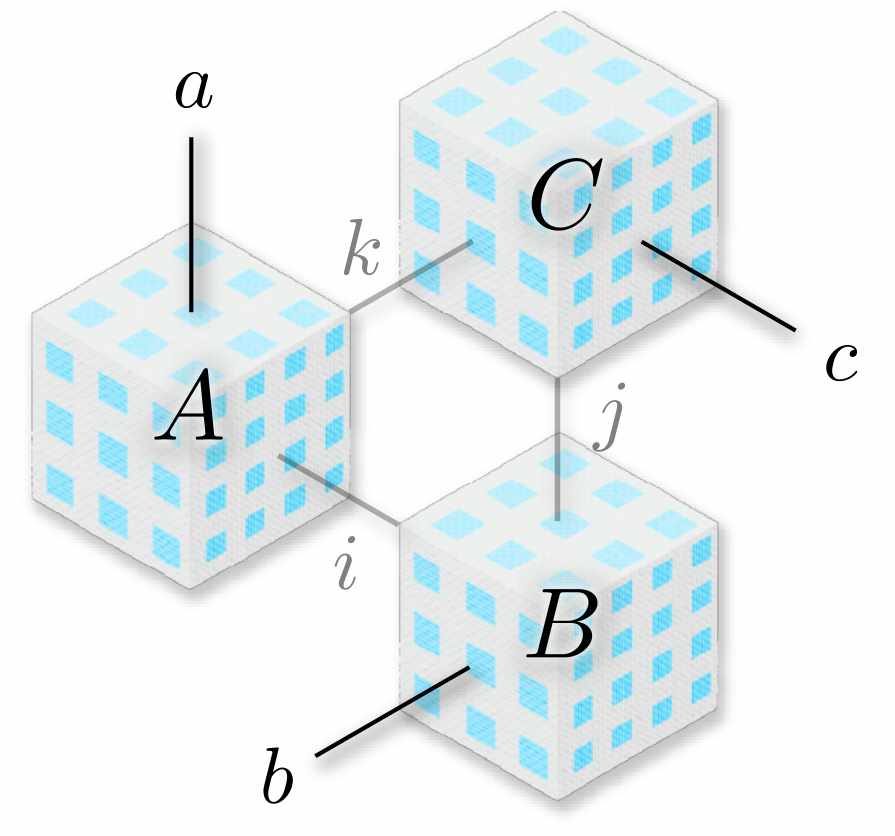
A hypercube product combines smaller cubes into a larger, structured shape. This visualization reveals how simple components can form complex group structures, enabling exact discovery of hidden patterns. (Source: arXiv:2511.23152)
Huh and colleagues have now supplied that proof, and it is as elegant as it is complete. The paper performs the first full optimisation‑landscape analysis of HyperCube on the fully observed target table. The core of the proof is a decomposition of the native objective H(Θ) into two terms: collinearity and an inverse‑ℓ₂ penalty. Collinearity measures how well the parameter matrices align along a common direction; the penalty pushes parameters away from zero while punishing large scales. The authors then establish a theorem they call the Collinearity–Associativity Equivalence: within the space of parameterisations, collinearity is exactly equivalent to associativity. This is the intellectual hinge of the whole construction. Once you know you are on the collinear manifold, the inverse‑ℓ₂ penalty morphs into an exact inverse rank penalty—the effective number of degrees of freedom is squeezed to be exactly the size of the underlying group—and the parameter matrices are driven to become a unitary, full‑rank representation of the group operation. The optimisation path, no matter where it starts, is levelled toward a unique, pristine algebraic structure.
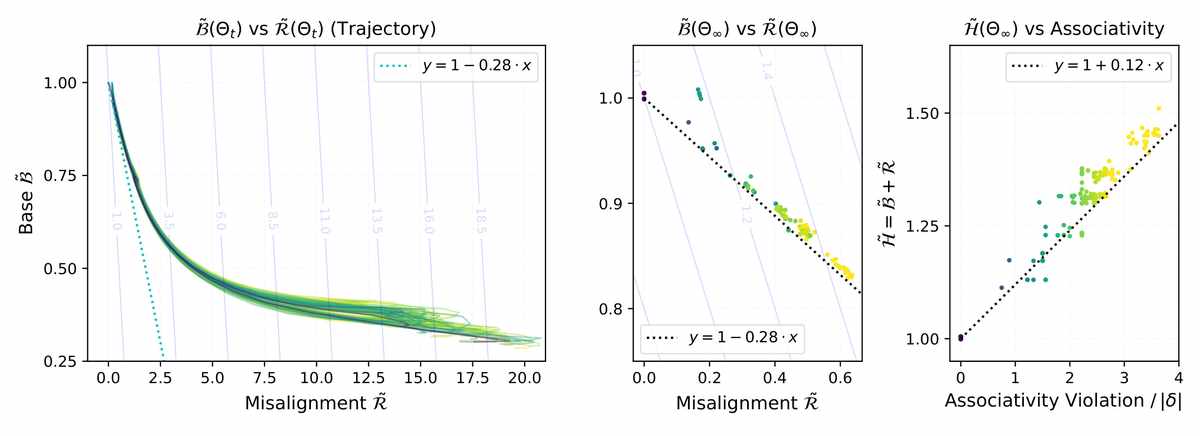
Optimization trajectories and converged minima cleanly separate associative structures from non-associative ones. This confirms the metric reliably measures algebraic complexity, enabling automated discovery of group structures. (Source: arXiv:2511.23152)
We should pause over the sheer strangeness of this result. A classical mathematician might ask: how can a continuous function—a sum of squared Frobenius norms, as bland as any least‑squares cost—decide the truth‑value of a universal algebraic equation? The answer, in this paper, is that the objective conspires to create a pressure that leaves no room for tables that are nearly associative but not quite. For any non‑associative target table, the collinearity term cannot be driven to zero, and the penalty term cannot collapse to the minimal value. The consequence is a hard floor: H(Θ) ≥ 3 |delta|, where |delta| is the table’s size, and equality is attained if and only if the target table is isotopic to a genuine group. In that sole case the parameters organise themselves into the regular representation of the group—the multiplicative table of the group itself, up to a harmless unitary gauge. There are no local minima that could fool an optimiser into thinking a non‑group table is a group; the landscape is as stern as a judge.
The authors have not merely asserted this; they have mechanised every theoretical result in Lean 4, ensuring that the chain of reasoning contains no hidden gaps. The small‑scale experiments that accompany the analysis follow the trajectories of the loss from thousands of random initialisations for diverse quasigroup targets. What emerges is a vivid picture: the optimisation paths flow relentlessly downward, and the converged minima cluster precisely according to each target’s intrinsic associativity violation. For the most associative tables, the residual loss touches the theoretical floor; for tables that violate associativity, it sits stubbornly above. The correlation is stark, yet the absolute bound is not gradational—it is a binary signal. A table either is a group to within an isotopy, or it is not.
Now comes the dialectical turn. A result this clean invites a pressing question, one that earlier work on low‑rank structures (Balzano et al., arXiv:2503.19859) has sharpened in other domains: what happens when the table is imperfect—noisy, incomplete, or only approximately associative? The current analysis is confined to the fully observed, noiseless regime. In that perfect setting the differentiable measure works like an algebraic oracle, but in the real world, data tables are rarely so pristine. The paper does not offer a lower bound on the associativity gap for non‑associative tables; it does not quantify how far a near‑group structure is from being a true group in a way that could guide an algorithm to rank plausible candidates. As the authors acknowledge in a dialogue with previous pioneers, this is an existence proof—a statement that the principle works under ideal conditions, not a packaged tool for messy tables. The measure is a compass that screams “North!” when you stand on pure group ground, but does not tell you whether you are a kilometre or a centimetre away when you are lost.
This tension is not a weakness so much as a demarcation of the frontier. Shaw’s recent work on optimal description length for deep learning (arXiv:2509.22445) has argued that a principle similar to Kolmogorov complexity can guide structure discovery in a broad class of models. The HyperCube result now offers an exact, rigorous instance of that philosophy: the algebraic complexity of a table is measured by a differentiable quantity whose global minimum picks out the simplest combinatorial structure—a group—with zero tolerance for error. The next step, hinted at by the dialogue with the authors of the original HyperCube proposal, is to explore whether softened versions of this measure can produce meaningful rankings for approximate or partially observed tables. Could a regularised variant, perhaps derived from the inverse‑ℓ₂ penalty in its rank‑penalising form, yield a continuous associativity gap that correlates with how “group‑like” a data set really is? That is an open question of considerable depth, and the current paper lays the theoretical foundation that makes it askable.
We should not underestimate the philosophical weight of what has been achieved. Mathematics has long taught us that discrete algebra and continuous geometry are distinct worlds: one is the realm of finite sets and operations, the other of smooth manifolds and flows. The fact that a plain gradient of a differentiable function can unerringly seek out a discrete algebraic object—a group—and reconstruct it with no prior knowledge of which group it is, feels like the discovery of a secret door between these two lands. It is reminiscent of the way the Atiyah–Singer index theorem linked the topology of a manifold to the analytic solutions of differential equations on it. Here the bridge is built not from geometry but from algebra, and the architect is a loss function whose only instruction is: be as collinear as possible, and don’t let your parameters grow without bound or vanish. The simplicity of the message belies its power.
What might this mean for the future? The experiment is, at present, an abstract one. But if the principle can be extended—if we can design differentiable measures that discover other algebraic structures (rings, fields, Hopf algebras) from data—then the way we search for hidden order in complex systems might change profoundly. Instead of pre‑committing to a discrete family of models and testing each one, we could let optimisation itself propose the algebraic scaffolding. The paper does not make the ambitious claim that this extension is easy, only that the first step is now on solid ground. “Perhaps,” as the authors are careful to convey, “when the data truly encodes a group, the loss knows.”
We are left with a humbling thought: that a smooth downhill walk, governed by nothing but arithmetic coherence, can lead a system to rediscover the genetic code of discrete symmetry. The question is no longer whether a differentiable measure can see groups; it is how far this vision can extend into the imperfect, noisy wilderness where real data live. The answer, for now, lies beyond the horizon—but the path to it has been lit by a proof that bridges the infinite and the finite with startling elegance.
References
- Dongsung Huh et al., A Differentiable Measure of Algebraic Complexity: Provably Exact Discovery of Group Structures, arXiv:2511.23152
- Xie et al., Equivariant Symmetry Breaking Sets, arXiv:2402.02681
- Balzano et al., An Overview of Low-Rank Structures in the Training and Adaptation of Large Models, arXiv:2503.19859
- Shaw et al., Bridging Kolmogorov Complexity and Deep Learning: Asymptotically Optimal Description Length Objectives for Transformers, arXiv:2509.22445