Now, you are probably thinking that the most urgent problem with AI in science is that it hallucinates, or that it cannot explain itself. But a deeper, quieter unease lurks beneath: even when AI models produce sensible answers — molecules for new drugs, causal diagrams of protein networks, recipes for chemical reactions — they rarely confess how much those answers depend on the shaky scaffolding of their own training. They say “here is a promising molecule” without adding “but that promise wobbles if the property predictor I relied on is biased.” For AI to be a true partner in scientific discovery it must learn to show its epistemic doubt, not just its confidence. A preprint (arXiv:2510.21523) from a team spanning Oxford, the Université de Montréal, and IBM Research now proposes a mathematical prism that does exactly this: it decomposes the opaque fog of model uncertainty into a coloured spectrum of vulnerability, revealing which step of a decision is fragile and why.
The team — spanning Oxford, the Université de Montréal, and IBM Research — is concerned with a class of AI called generative flow networks, or GFlowNets. Think of a GFlowNet as an explorer that builds complex objects — a catalyst, a molecular fragment, a causal graph — one piece at a time, like a chef assembling a dish ingredient by ingredient from an infinite pantry. At each step the network decides what to add next, guided by a reward model that predicts how good the finished object will be. If the reward model were flawless, the GFlowNet would learn to cook with perfect judgement. But reward models are themselves trained on finite, noisy data; they are faulty maps of the territory. The GFlowNet therefore inherits an uncertainty of a special kind: it is not uncertain about the outcome of a coin toss, but about its own map — an uncertainty about uncertainty, which philosophers call epistemic.
Teams already gauge this epistemic fog by training several GFlowNets on slightly different versions of the reward model, an ensemble, and watching how their decisions scatter. The wider the scatter, the greater the uncertainty. The problem is that an ensemble gives you only a single number — the total fog — not a picture of where the fog is thickest. Which ingredient choice is the wobbliest? Is the catalyst selection robust while the additive choice trembles? The ensemble cannot tell you. It is like trying to navigate a city with a single visibility reading for the whole urban area; you know it is foggy, but not whether the bridge is invisible or just the side street.
The team’s insight is to bring a mathematical technique, polynomial chaos expansion (PCE), to the problem like an epistemic X‑ray. PCE has been a workhorse of engineering for decades, used to see how uncertainty in a dozen parameters propagates through a jet engine or a climate model. Here the authors fit a PCE surrogate to a small ensemble — maybe a dozen GFlowNets — and extract from the surrogate’s coefficients something called Sobol sensitivity indices. These indices act as a prism: the murky, white‑light total variance enters, and it exits as a spectrum of separate colours, each one telling you how much each component of the reward model’s disagreement is responsible for the shakiness of a particular decision. The “colours” are the principal components of the reward‑model variation, which the authors label with intuitive roles: the global offset, the peak‑versus‑bulk sharpness, the localised disagreement, the cross‑factor coupling, and the fine‑scale tail.
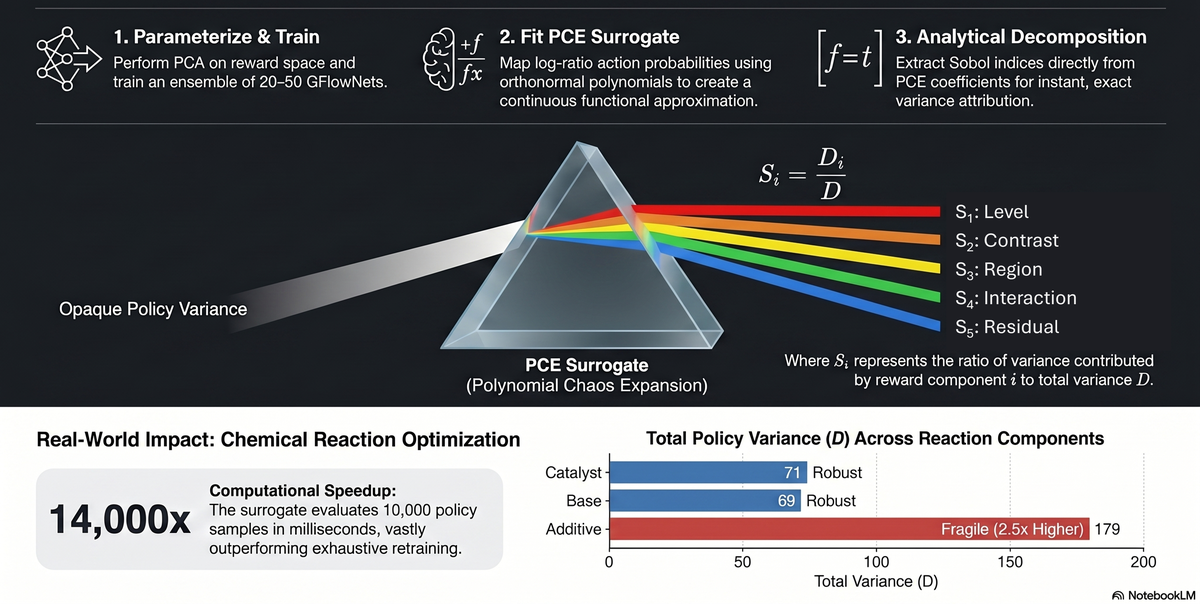
A polynomial chaos surrogate splits a model’s decision uncertainty into interpretable components, revealing that additive selection in a chemical reaction is far more variable than catalyst or base choices. This insight allows researchers to quickly identify fragile steps without retraining the full model. (Source: arXiv:2510.21523)
Of course, a real prism works only because sunlight is a mixture of independent spectral components; the mathematical prism works only if the reward‑model variations can be treated as independent random variables. The team already uses a principal‑component decomposition to squeeze the variation into uncorrelated directions, but uncorrelated is not the same as independent, and that gap is exactly where the prism’s light could be somewhat splintered. An important question sharpened by earlier work on polynomial chaos expansions for operator learning (Sharma et al., arXiv:2508.20886) is whether the independence assumption holds in practice; the present paper acknowledges that it has not been verified, making the interpretability edge that the method offers still tethered to a hypothesis.
Nevertheless, the results burn with practical significance. In the Buchwald–Hartwig reaction, a workhorse of pharmaceutical synthesis, the prism reveals a sharp divide: the choice of catalyst is robust (total policy variance around 71), but the later selection of an additive is fragile — its variance is roughly 179, a two‑and‑a‑half times larger wobble, driven by a specific component of the reward model’s variation. Without the decomposition, a chemist would see only a single uncertainty number and might misattribute the fragility. In fragment‑based molecular design, the conventional wisdom says that the molecule's scaffold is where the biggest uncertainty lives; instead, the Sobol spectrum shows that the linker position (variance around 28) is the most sensitive step — roughly twice as uncertain as the decoration positions (variance as low as 14–18). The intuition is reversed. For the Sachs protein signalling network, the sensitivity indices separate the MAP‑kinase cascade edges from the PKA and PKC hub edges into two distinct regimes — essentially a to‑do list for experimental biologists, telling them which edges to probe first because they are most affected by model uncertainty.
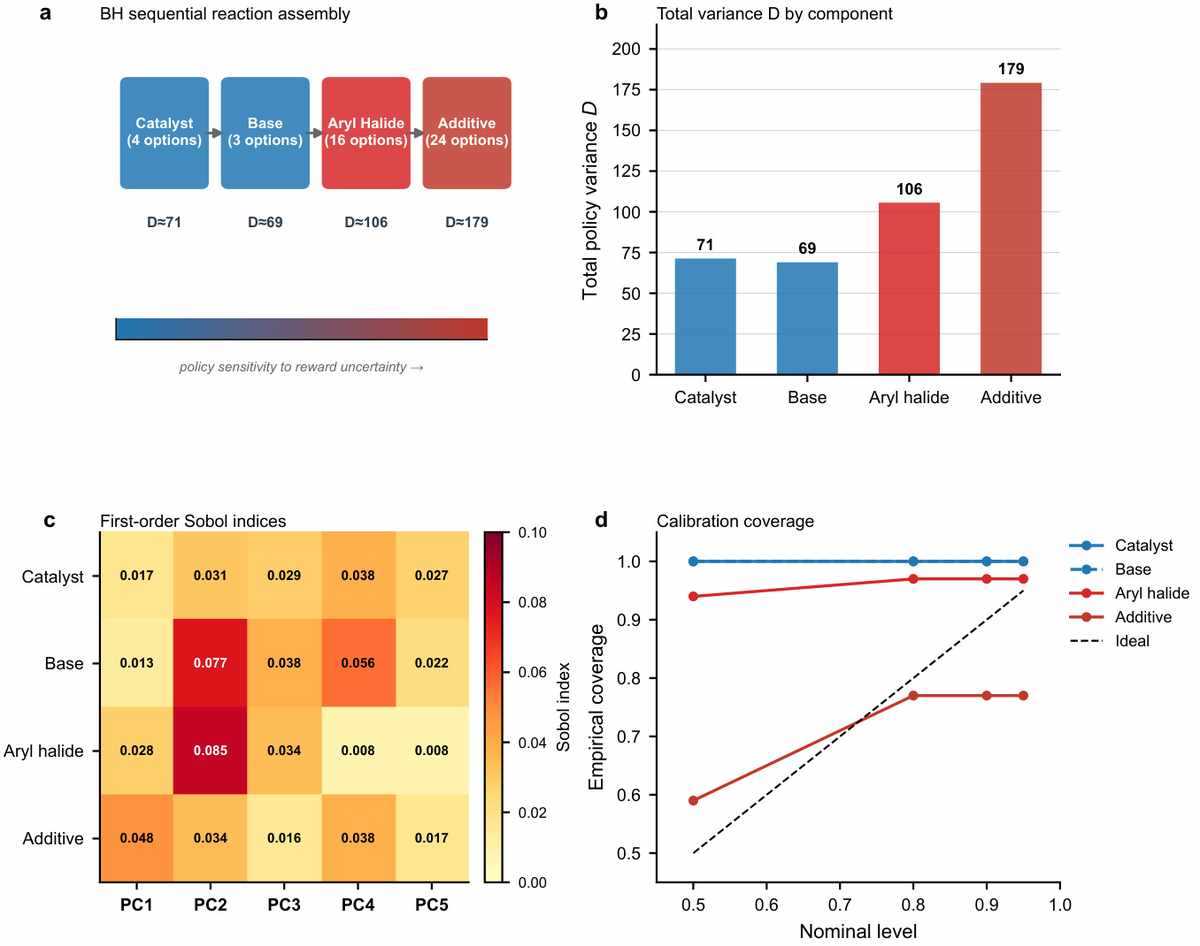
Additive selection is the most fragile step in building reaction conditions, while catalyst choices are robust. This pinpoints where uncertainty lurks, guiding chemists to focus efforts for more reliable yield predictions. (Source: arXiv:2510.21523)
The computational advantage is also dramatic: the PCE surrogate can evaluate ten thousand policy samples in milliseconds, thousands of times faster than training an entirely new ensemble from scratch. This makes it feasible to scan large chemical spaces or to embed the uncertainty analysis into an interactive design loop, where a scientist asks “what if I distrust this training subset?” and the prism reddens the fragile steps in real time.
A further layer of rigour comes from the way the team grounded their theoretical convergence guarantees. Four of the five guarantees have been formally verified with the Lean 4 proof assistant, a rare level of certified mathematics in machine‑learning research. The proofs do not remove the independence caveat, but they do assure us that when the inputs behave, the surrogate will work. In a world where AI results often float on a sea of unreproducible claims, that formal backbone is itself a quiet statement.
The road ahead winds through that independence question. If future work can justify treating the principal components as independent, perhaps through copula transforms or by designing orthogonal reward ensembles, the prism would become a certified instrument. Until then, the method offers a partial map of uncertainty — partial, but enormously more informative than a single fog number. More fundamentally, the work forces us to ask what it means for an AI to know its own ignorance. A perfect predictor of epistemic doubt may be impossible, but a map that shows which decisions are most hostage to imperfect training data is a step toward an artificial scientist that can say, not just “I predict X,” but “I predict X, and here is which part of my prediction you should take with a grain of salt.” That confession of fragility may be the most honest gift an AI can give to the humans who would trust it with designing drugs, unravelling diseases, or navigating the fog of scientific discovery itself.
References
- Ram’on Nartallo-Kaluarachchi et al., Interpretable epistemic uncertainty decomposition in sequential generative models via polynomial chaos surrogates, arXiv:2510.21523
- Sharma et al., Polynomial Chaos Expansion for Operator Learning, arXiv:2508.20886