
What if the invisible grid that gives every sentence its shape—the distinction between a noun, a verb, an adjective—was never a rule handed down by grammarians or hardwired by evolution, but simply fell out of the act of predicting what comes next? This is the unsettling possibility raised by a new preprint (arXiv:2605.24585) from Immertreu and colleagues, who trained a deep neural network not to guess the next word, but to paint a landscape of words likely to appear many steps ahead. They did not teach it about syntax, parts of speech, or even the concept of a “word category.” They simply asked it to predict the future. What emerged was grammar.
The experiment draws on a framework from reinforcement learning called successor representations. In the classic setting, an agent navigating a maze learns not just which room it will enter next, but the expected future occupancy of all rooms, weighted by how soon they will be visited. Translate “rooms” to “words,” and you have a new way to read text. Instead of training a model to maximize the probability of the immediate next token—the standard recipe behind large language models—Immertreu and colleagues trained it to produce a probability distribution over all possible future words, summed across multiple horizons and discounted by distance. Think of it as the difference between a tourist who only looks at the next street sign, and one who carries a mental map of the entire neighborhood, with the upcoming café looming larger than the park ten blocks away.
The team embedded a 20,000-word vocabulary into a deep residual network and trained it on 103 million tokens of English text from WikiText-103. Three separate prediction heads looked ahead with different decay rates, capturing structure at short, medium, and long temporal scales. The network’s single task was to minimize the mismatch between these multi-horizon predictions and the actual future word distributions—no linguistic labels, no grammatical supervision. It was, in effect, learning to forecast the linguistic weather.
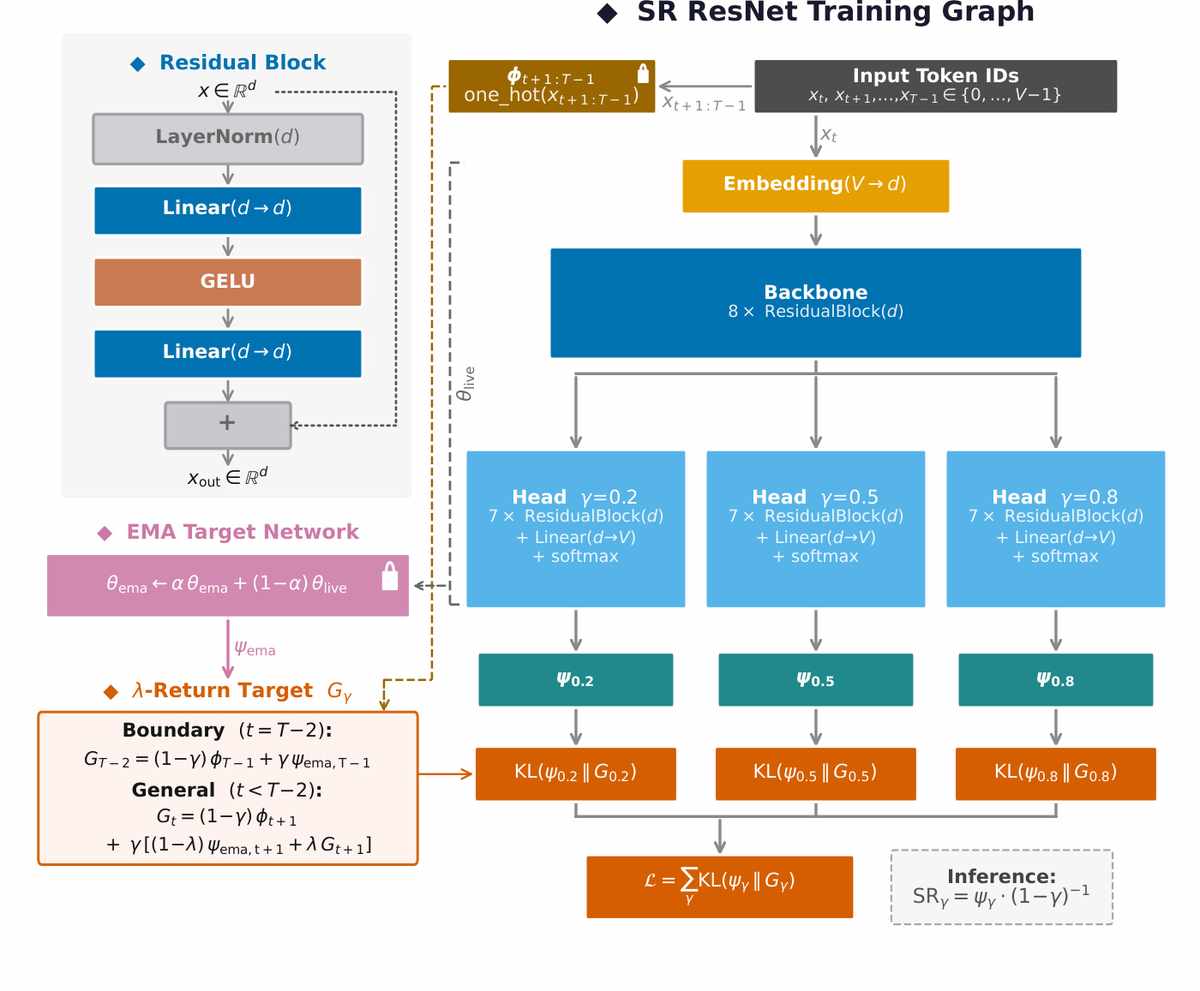
Input words flow into three separate prediction streams, each tuned to a different time horizon. This design helps the model discover word categories like nouns and verbs from the patterns of surrounding words. (Source: arXiv:2605.24585)
Then came the surprise. After training, the team examined the geometry of the network’s internal representations using dimensionality reduction and unsupervised clustering. Before training, the word embeddings formed a structureless cloud, points scattered without rhyme or reason. After training, they had spontaneously organized themselves according to part-of-speech categories. Nouns, verbs, and adjectives separated into three visibly distinct regions. At higher resolution, subcategories bloomed within each cluster—animate nouns settling near other animate nouns, action verbs near other action verbs. The network had not merely learned to predict; it had, as a byproduct, carved the grammar of English into its own representational space.
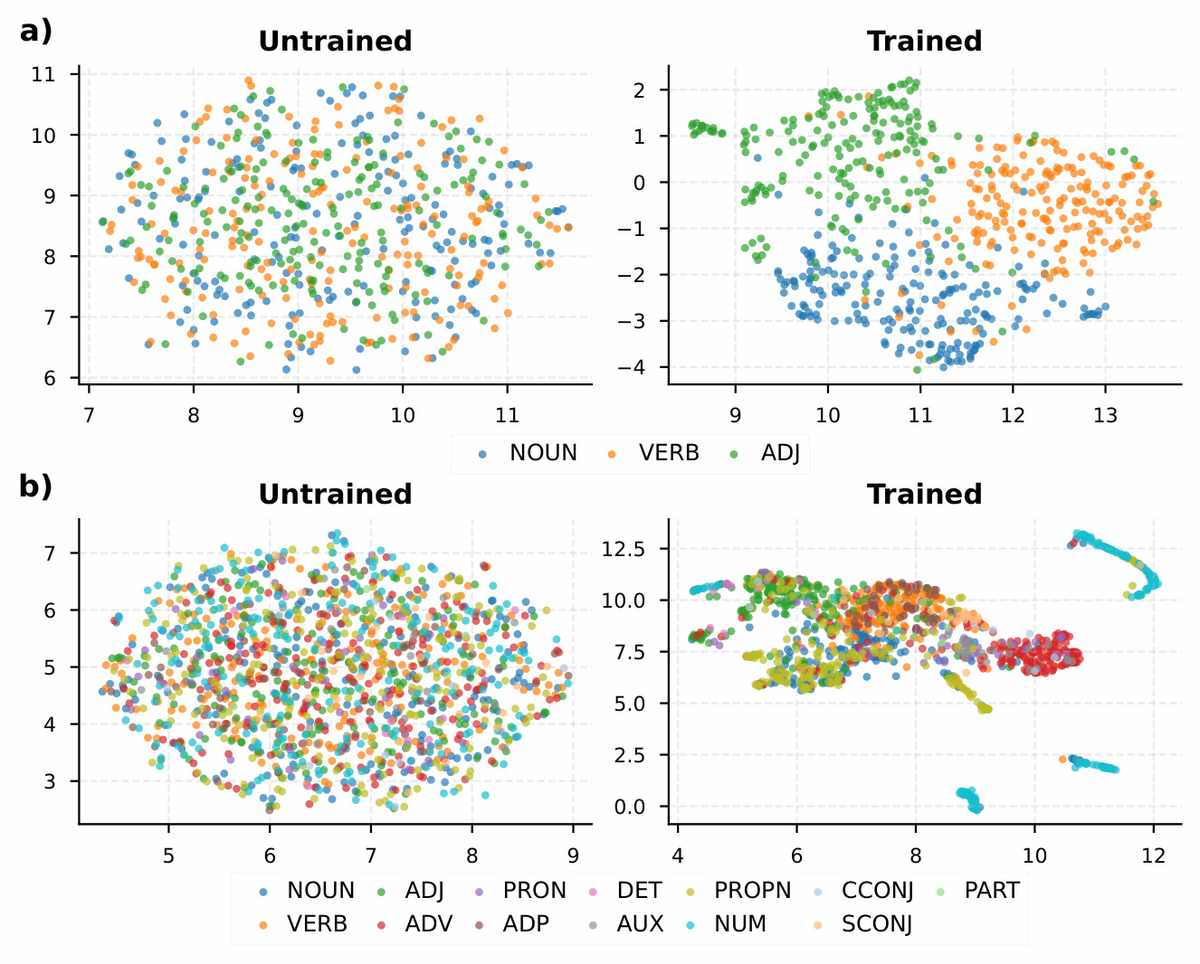
After training, words naturally cluster by part of speech—nouns, verbs, and adjectives form distinct groups. This shows that a simple learning rule can spontaneously organize language's grammatical structure without explicit instruction. (Source: arXiv:2605.24585)
An important question arises here, one that echoes through decades of debate in linguistics and cognitive science: is this merely statistical co-occurrence masquerading as understanding? After all, nouns tend to follow determiners, verbs tend to follow nouns, and adjectives often precede nouns. Perhaps the network simply learned these shallow correlations. The researchers anticipated this objection and tested a revealing diagnostic: the temporal horizon, the parameter gamma that controls how far into the future the network looks. When gamma was set small—when the network gazed only a few words ahead—the syntactic clustering was sharpest. When gamma was set large—when it tried to anticipate distant future words—the categories began to blur, integrating broader contextual information and semantic associations. Short-term prediction sharpened syntax; long-term prediction softened it. If the network were merely memorizing local co-occurrence statistics, the horizon would not matter. Its systematic dependence suggests that something deeper is going on.
Here the allegory shifts from weather maps to the growth of an unplanned city. If you watch the accumulated footsteps of thousands of citizens moving between homes, markets, and temples, paths emerge in the dirt. No one decreed a street grid, but the paths form along the lines of maximal utility, the geometry of desire. Words, too, are shaped by the pressure of predictive utility. A verb that must anticipate its object finds itself pulled toward the region of space occupied by objects; a noun that must anticipate a verb becomes a natural source of predictions, its embedding acquiring a different gravitational signature. The resulting “neighborhoods” in the representational landscape are not assigned by a planner—they are worn into existence by the ceaseless forward-looking pressure of the language stream.
This sits in an interesting dialogue with earlier work on distributional semantics, which showed that words with similar meanings cluster together because they appear in similar contexts. The new twist is that successor representations are not merely retrospective—they are fundamentally prospective. They answer not “what contexts did this word appear in?” but “what words will appear next, and next, and next?” The syntax that emerges is thus not a static map of co-occurrence but a dynamic map of anticipatory structure. It is grammar as a prediction engine.
The philosophical upshot is difficult to ignore. For decades, linguists debated whether the brain possesses an innate “language organ” pre-loaded with syntactic categories, or whether those categories are acquired through experience. This work offers a third perspective: perhaps syntax is not built in or explicitly learned, but self-organises as an inevitable consequence of trying to predict the temporal flow of language. The network does not need to know what a “noun” is; the concept of noun-ness precipitates out of the optimisation landscape, much as snowflakes form when water vapour is driven toward equilibrium. There is no instruction, only pressure.
That said, the limitations are plain. The model was trained on a relatively small corpus—a 103-million-token slice of an encyclopedic dataset—and the vocabulary was pruned to 20,000 words. The clean clustering observed for nouns, verbs, and adjectives becomes messier when extended to the full 13-category part-of-speech set, where most categories huddle in a dense central region while a few—numerals, notably—project as isolated strands. Whether the same spontaneous geometry would arise in a model trained on truly massive, noisy, multilingual data is an open question. The team themselves note that they have only begun to map this representational space.
Yet the direction is clear. If prediction alone can carve syntactic joints, then perhaps the entire edifice of language—its morphology, its phrase structure, its capacity for recursion—may be understood not as a set of innate constraints, but as the frozen form of a forward-looking dynamical system. This resonates with the emerging framework of predictive processing in neuroscience, which casts the brain as a prediction engine that constructs a model of the world by constantly trying to anticipate sensory input. Language, in this view, is not a separate faculty but a particularly elegant playground for the brain’s core computational strategy.
We are left, then, not with a tidy resolution but with a sharper question. If the structure of language can emerge from the simple mandate to predict, what other structures—concepts, categories, perhaps even the architecture of conscious thought itself—might arise from the same pressure? The successors in the model’s name may turn out to be not just distributions over words, but the hidden architects of cognition. We are only beginning to see what prediction builds when we let it run long enough.
References
- Mathis Immertreu et al., Word Class Representations Spontaneously Emerge from Successor Representations Trained on Natural Language, arXiv:2605.24585