
Imagine a traveller lost in a thick fog at dawn. As the sun rises, the mist thins, slowly revealing the contours of the landscape — first the nearby trees, then the distant hills, until the entire valley is sharp and clear. The traveller never has to know the whole layout at once; she just waits as the world emerges around her. This is not a scene from a pastoral novel. It is, in a precise mathematical sense, how modern generative AI creates everything from photorealistic faces to novel protein structures. The process is called a diffusion model, and until recently, its deep connection to an old idea from quantum mechanics — adiabatic transport — has been hiding in plain sight.
In a preprint (arXiv:2606.05217), a team led by Boris Hanin at Princeton University’s ORFE Department, together with Peter Halmos in Computer Science, reveals that the step‑by‑step denoising at the heart of diffusion models can be recast as a quantum system drifting through an energy landscape. They call the central object the Score Hamiltonian. The mapping is exact, and it ends the mystery of why these models sample data so reliably: they are performing an adiabatic evolution, the same kind of slow, guided change that keeps a quantum particle in its ground state. This perspective hands us a new fundamental limit — a kind of speed limit for sampling — and, perhaps more importantly, a new language for talking between physics and artificial intelligence.
To appreciate the scale of the reframing, it helps to recall how diffusion models are usually understood. The standard recipe, crystallised by Ho et al. in their denoising diffusion probabilistic model (DDPM), injects noise into data until it becomes pure static, then trains a neural network to reverse that corruption. The training objective measures how well each denoising step recovers the original signal — a clever accounting trick that can be framed as a variational lower bound. This approach, scaled up by Rombach et al. into latent diffusion models, now powers the image‑generation revolution. Yet the standard story treats the reverse process as a sequence of small Markov jumps, with the learning signal coming from a score function that points toward cleaner data. It is a powerful but conceptually disjointed picture: the mathematics of training does not obviously explain why the sampling dynamics work.
Halmos and Hanin inject conceptual unity by asking a quantum‑mechanical question: what if, at every stage of the diffusion, the noisy distribution could be seen as the lowest‑energy configuration of a properly chosen Schrödinger operator? In quantum mechanics, a Hamiltonian defines the energy of a system, and its ground state is the most stable arrangement. If you change the Hamiltonian slowly enough, the adiabatic theorem guarantees that the system stays in its instantaneous ground state — it flows gently from one configuration to the next without jumping to excited levels. The Princeton team showed that the score function, which is the very gradient the neural network learns, can be woven into a quantum potential. When plugged into a standard Schrödinger equation, this potential builds a Hamiltonian whose ground state is exactly the model’s estimate of the data at that noise level. The denoising trajectory then becomes an adiabatic passage: as the noise scale dials down, the Score Hamiltonian changes, and the system tracks its shifting ground state, landing on the clean data distribution when the noise vanishes.
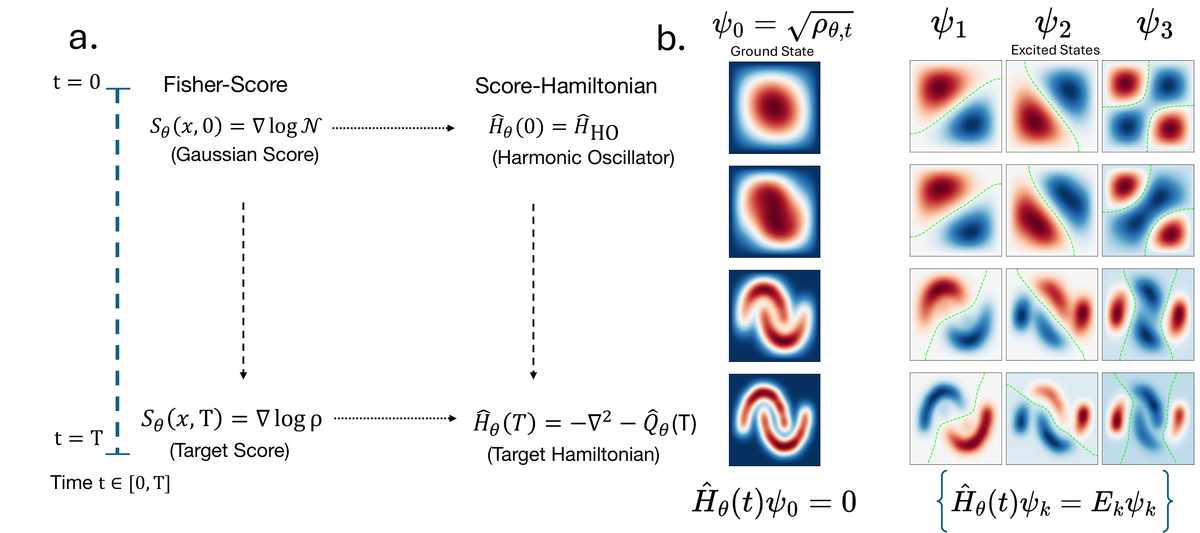
Diffusion models map to a Hamiltonian whose ground state encodes the evolving data density. This connection reveals hidden structure behind diffusion dynamics, opening doors to faster or more efficient models. (Source: arXiv:2606.05217)
Think of a pendulum whose string is slowly shortened by a gentle hand. If the hand moves gradually, the pendulum continues to swing smoothly, never jerking or breaking its rhythm. In quantum mechanics, the adiabatic theorem governs systems whose parameters change slowly in just this way — they remain in their ground state, adjusting gently to the new conditions. The reverse diffusion of a generative model, seen through the Score Hamiltonian, is precisely such an evolution. Only here, the “hand” shortening the string is the learned score function itself, and the “pendulum” is the entire ensemble of noisy data points. This is not merely an analogy; the correspondence is an exact mathematical identity.
From this mapping, the team derives a clean bound on the quality of the final samples. The total variation distance between the generated and true data is governed by the ratio of two numbers: the squared error of the learned score function, and the spectral gap of the Score Hamiltonian — the energy chasm between its ground state and its first excited state. A large gap means the ground state is well separated, and even a less‑than‑perfect score model can keep the system on track. A tiny gap, on the other hand, makes the system dangerously sensitive; even small errors in the score can slosh the state into an excited configuration, corrupting the sample. The spectral gap turns out to be the inverse Poincaré constant of the data density, a quantity that measures how easily probability mass can flow between modes. When data lives in many narrow, well‑separated clusters, the gap shrinks, and sampling becomes inherently difficult — a statement that feels intuitively right but had never been crystallised so sharply.
The team put their bound to the test on systems where the spectral gap can be calculated, or at least estimated. They trained a diffusion model on samples from a single hydrogen‑atom orbital and showed that the spectrum of the learned Score Hamiltonian lines up with the exact quantum energies — not approximately, but with an accuracy that confirms the mapping is not just a theoretical nicety. On a coupled harmonic oscillator and on the classic two‑moons density, they demonstrated that the sampling error scales linearly with the score error divided by the square root of the gap, exactly as the bound predicts. When they designed the noise schedule — the speed at which the diffusion time progresses — using the gap itself, the model’s sample quality became far less sensitive to the total number of steps. In short, the adiabatic lens yields a principled way to choose how fast to denoise, something that has traditionally been left to heuristics.
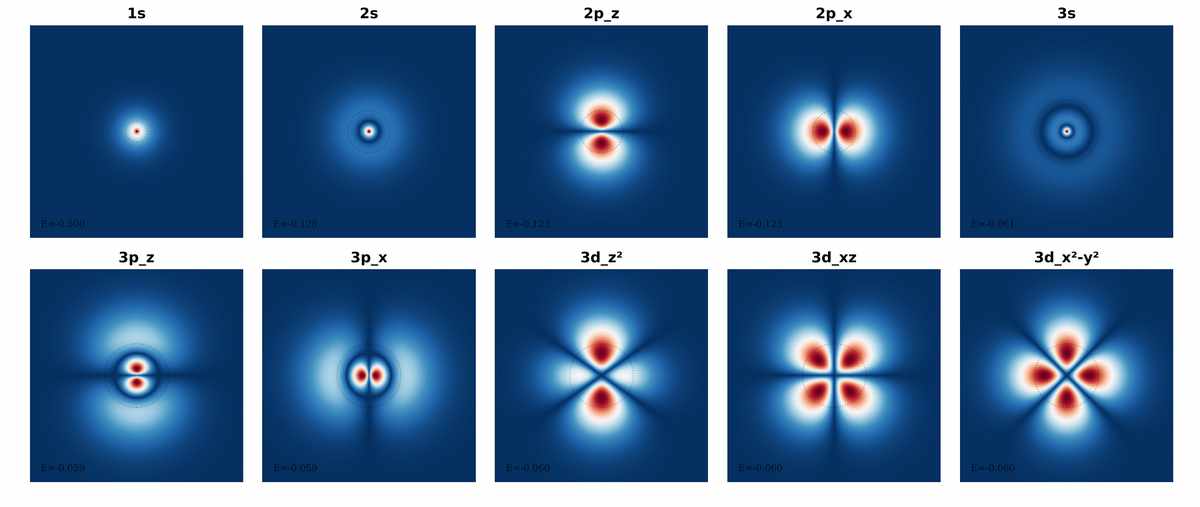
The Score Hamiltonian reconstructs the exact shapes of hydrogen atom orbitals from just ground-state data. This proves diffusion models can uncover hidden quantum structures, bridging machine learning and fundamental physics. (Source: arXiv:2606.05217)
An important question raised by the original DDPM framework, and sharpened by the latent‑diffusion explosion, is whether such a spectral bound can ever be a practical tool rather than a post hoc explanation. The spectral gap, after all, is notoriously hard to compute for the high‑dimensional, multimodal distributions that real‑world generative models handle — think of the manifold of all human faces. Halmos and Hanin are candid about this: the bound is an asymptotic floor, not a number you can plug into a training loop. In exchanges with the earlier works, the idea that a variational lower bound already gives a perfectly serviceable training signal sits in an interesting tension with the new bound’s promise. Yet the authors’ response is characteristically measured: the value of the mapping is not to replace existing objectives but to open a door. If the gap is small in a particular region of the data space, that is where the score model must be most accurate. Future training schemes might allocate representational capacity according to the local spectral gap, a strategy that would have been invisible without the quantum analogy.
The connection also resonates with a parallel strand of generative modeling: flow matching, introduced by Lipman et al., which replaces the stochastic diffusion process with an ordinary differential equation. That deterministic transport is already known to share deep mathematical ties with optimal transport and, intriguingly, with Schrödinger bridges. The Score Hamiltonian reframes that relationship too, hinting that flow‑based models might also be analyzed through a spectral lens, and that the adiabatic theorem could yield new bounds for deterministic samplers as well.
Philosophically, what Halmos and Hanin have done is to reveal that the success of diffusion models is not a mere engineering triumph but a reflection of a principle that nature itself obeys. The adiabatic theorem is one of the most universal laws of quantum physics, and seeing it at work inside a neural network suggests that generative AI and fundamental physics are not separate continents but adjoining districts, separated only by the language we use to describe them. The Score Hamiltonian is a bridge between the two, a reminder that the same mathematics that governs how a superconductor cools through its transition temperature also governs how an image emerges from noise.
Perhaps the most subversive implication is this: the bound may ultimately be less important than the questions it invites. If sampling quality is controlled by a spectral gap, can we engineer data representations that widen that gap? Can we design score architectures that are provably adiabatic, rather than merely hoping that a large step budget will suffice? These are not incremental engineering questions; they cut to the heart of how we think about the geometry of data. The traveller in the fog, it turns out, was never truly lost; she was simply waiting for the landscape to reveal itself, one quantum step at a time. The compass was always there, hidden in the mathematics, waiting for someone to pick it up.
References
- P. Halmos and B. Hanin, The Score Hamiltonian: Mapping Diffusion Models to Adiabatic Transport, arXiv:2606.05217
- J. Ho et al., Denoising Diffusion Probabilistic Models, arXiv:2006.11239
- R. Rombach et al., High-Resolution Image Synthesis with Latent Diffusion Models, arXiv:2112.10752
- Y. Lipman et al., Flow Matching for Generative Modeling, arXiv:2210.02747