
Most scientific datasets are like a stack of completed jigsaw puzzles — beautiful, complete, but utterly silent about which piece went in first. You see the final arrangement; you can never trace the hand that built it. A preprint (arXiv:2606.07865) from Daniel N. Wilke at the University of the Witwatersrand argues that we need a new kind of data — data that not only shows us the finished puzzle but carries an entire workshop inside it, complete with a set of alternative puzzles it could have become, a record of why it didn’t, and the ability to answer the question that matters most in science: What would have happened if I had changed this one thing?
This is not a minor upgrade. It is a re‑engineering of what a data point is.
Scientific machine learning, Wilke observes, is throttled not by the size of the models but by the poverty of the training data. Observational data — measurements from telescopes, sensors, patients — records outcomes but not the mechanisms that generated them. Template synthetic data, from simulations, embeds a generating process, but only for the simulator’s own template, not for the specific case a scientist cares about. Both are, in a deep sense, causally incomplete. The proposal, laid out in the paper, is a third option: instrumented data, in which every datum carries the mechanistic model that produced it, an explicit uncertainty over that model, and an executable family of counterfactuals.
To appreciate what this means, think of a traditional dataset as a collection of witness statements after a traffic accident. You know where the cars ended up, but you cannot rerun the collision to test whether that puddle of oil changed the skid. Instrumented data is more like a black‑box recorder that also contains a miniature physics simulator: it tells you not only the final positions but also what the trajectory would have been if the road had been dry, or if the driver had braked half a second later. And it tells you how sure it is about each reconstruction. The data point doesn’t just sit there; you can interrogate it with “what‑if” questions, and it answers with a new scenario backed by the same mechanistic laws.
This is not science fiction. Wilke’s team describes a concrete realisation: a verification‑and‑validation (V&V) instrumented image‑to‑simulation pipeline. In such a pipeline, a sensor observation — a photograph of a cracked bridge, a micrograph of a biological structure, a radar image of a storm — is converted into a fully specified, solver‑backed simulation with editable parameters. A human domain expert validates the initial conversion. A subsequent “agent‑update” operator, trained on the expert’s residuals, learns to approximate that validation automatically for a fixed problem class, gradually replacing the human‑in‑the‑loop for routine cases. The result is a computational object that is rich, causal, and shockingly versatile.
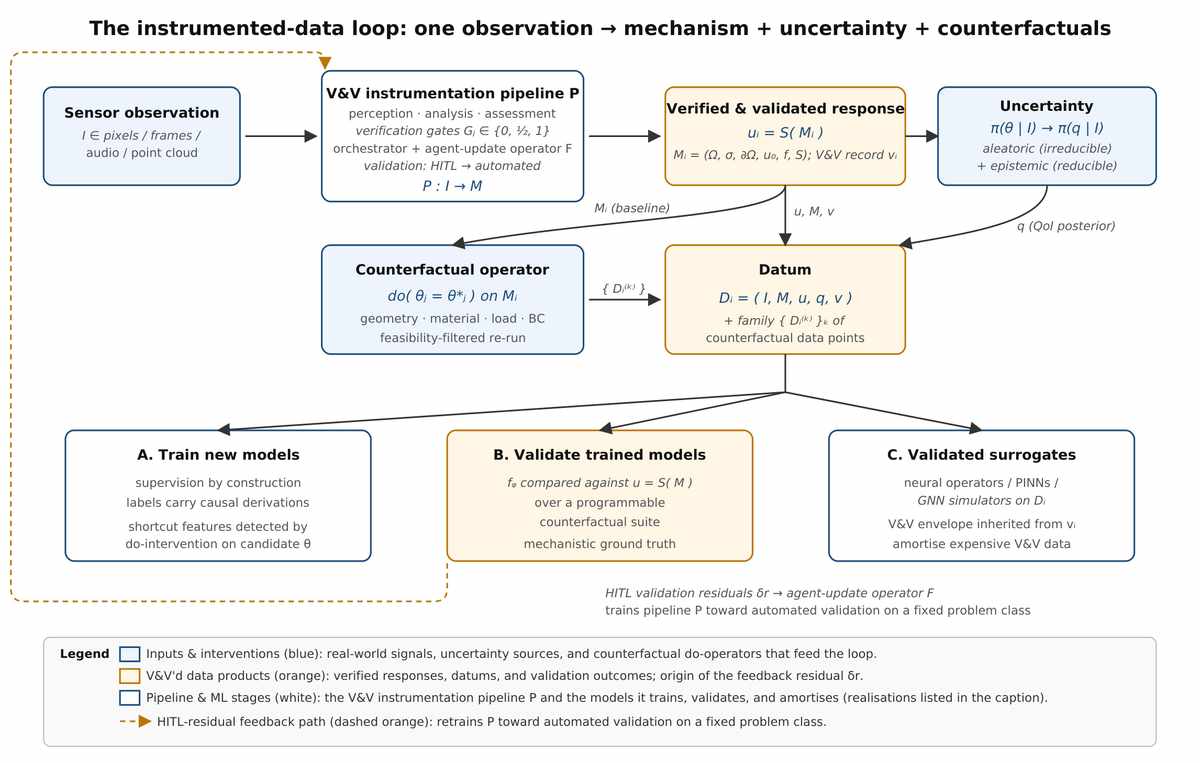
Sensor data flows through a validation pipeline to produce verified responses with measured uncertainty, feeding multiple uses like model training and testing. This loop automates expert validation, making scientific machine learning more reliable and scalable. (Source: arXiv:2606.07865)
The paper identifies five ways such instrumented data could be consumed. Three sit downstream of the pipeline: training new models, validating existing models against mechanistic ground truth, and training validated surrogate networks that amortise the cost of running the full simulation every time. Two further uses are more strategic. One is pretraining — fewer but far richer inputs for foundation models that aim to reason about scientific phenomena. The other is a vision of on‑demand reasoning: a large language model, at inference time, invoking an instrumented‑data pipeline to answer causal questions it could never resolve from text alone. Data, in this framework, becomes not just a resource for training but an active participant in scientific argument.
At the heart of the proposal lies Pearl’s do‑operator, a formal way of expressing intervention: what happens if we do set a parameter to a particular value, regardless of what normally determines it? Synthetic data built on a fixed template cannot answer that; the template never varies. Observational data can only show you correlations, never the consequences of deliberate tampering. But instrumented data, by carrying an editable mechanistic model, supports causal interventions natively. You can ask: what if I change the material of this component? What if the ocean temperature were two degrees higher? The data answers by running the modified model and showing you the consequences, all while tracking how much of your uncertainty is due to irreducible randomness and how much to gaps in your knowledge.
This decomposition of uncertainty — into aleatoric and epistemic components — is one of the paper’s most important claims. Aleatoric uncertainty is the noise inherent in the world; epistemic uncertainty is the ignorance we bring to it. Instrumented data is meant to propagate both through the simulation, giving you not just a best‑guess prediction but a distribution of possibilities and a clear audit trail of what you know and what you are still guessing about. Yet the extraction step — the operator that turns a raw image into a mechanistic model — is precisely where the proposal is still at its most exploratory. In a related work, Wilke's own multi-agent modeling system (arXiv:2604.06788) demonstrated how to automate the building of computational models from perception. That earlier effort left open a delicate question: can the extraction of model parameters from noisy, ambiguous sensor data ever be made fully automatic and trustworthy, or will it always require a domain expert's judgment to decide what constitutes a valid mechanism? The instrumented‑data paper is honest about this tension. For now, the extraction operator returns interval bounds and probability densities, but the validation remains a human‑in‑the‑loop affair. The ambition — only partially demonstrated — is to migrate toward automated validation on fixed problem classes.
The paper also draws a boundary around itself by distinguishing two regimes for an instrumentation pipeline acting as a reviewer of other work. Inside its own validation envelope — a familiar physical domain, with shared constitutive laws, gate checks, and code‑compliance standards — a mature pipeline could, the authors argue, produce independent mechanistic assessments that complement human peer review. Outside that envelope, in a different physical domain, the same pipeline would risk confusing its own training artefacts with genuine insight. The distinction is a quietly subversive one: it suggests that the most realistic path toward automated scientific reasoning is not a single omniscient AI but a mosaic of domain‑specific pipelines, each carrying its own physics, each maturing through its own community of experts. The universal scientist, in this picture, may never arrive — and that might be a feature, not a bug.
For all its ambition, the work is a perspective piece. No large‑scale experimental demonstration yet exists; the uncertainty‑extraction operators have not been stress‑tested across the sprawling diversity of real scientific instruments. Yet the conceptual architecture is clear enough to set a research agenda. In fields as varied as computational biology, climate modelling, materials science, fluid mechanics, and medical imaging, instrumented data promises to move machine learning from pattern recognition toward causal understanding — from correlation engines to tools that can genuinely be used to design experiments, not just to analyse them.
Perhaps the deepest implication concerns the future of foundation models for scientific reasoning. The current generation of large language models is brilliant at pattern completion but baffled by counterfactuals — they cannot distinguish between what did happen and what could have happened, because their training data never taught them the difference. Instrumented data offers a way to supply that missing education. Each datum is, in effect, a miniature laboratory that can be manipulated. A model trained on such data would not merely learn to mimic scientific text; it would learn to reason about interventions, to audit its own uncertainty, to ask “what if” and receive a mechanically rigorous answer.
One might object that this is only pushing the modelling problem further upstream: someone still has to build the mechanistic models that instrument the data. That is true, but it misses the scale transformation. A single expert constructing one simulation creates a template. A pipeline that converts thousands of sensor observations into instrumented data creates a causally rich training corpus that can subsequently serve many downstream consumers — including automated validation tools that, in turn, accelerate the pipeline itself. The virtuous cycle is the whole point.
In the end, instrumented data might not change which predictions are possible tomorrow, but it could change why we trust those predictions. A forecast that comes with its own causal wiring diagram, its own uncertainty budget, and its own admission of what it does not yet know is a fundamentally different kind of information. It is data that, like a good scientist, can say: I think this is why it happened. Here is how sure I am. And, by the way, if you want to see what would happen under different conditions, I can run that for you right now.
We are a long way from that world. The extraction operators need to be hardened. The validation envelopes need to be mapped. The community of experts that sustains each domain‑specific pipeline still needs to be organised. But the blueprint has been drawn. The paper is not a finished cathedral, but it is a detailed architectural plan — one that invites engineers, domain scientists, and machine‑learning researchers to start laying the foundations.
References
- Daniel N. Wilke, Instrumented data for causal scientific machine learning, arXiv:2606.07865
- Daniel N. Wilke, From Perception to Autonomous Computational Modeling: A Multi-Agent Approach, arXiv:2604.06788