
Think of a chess grandmaster, mid-game: a flick of the eyes across the board, a mental leap to a configuration ten moves out, and a quiet conviction that the path is sound. The grandmaster doesn't plan one move at a time — that way lies combinatorial explosion. They work in chunks, in strategic themes, in chapters. The question that haunts modern robotics is whether a machine can learn to plan the same way, not by brute-force search through millions of primitive joint angles, but by composing its world into a story with a beginning, a middle, and an end.
For years, the most promising answer came in the form of latent world models — neural networks that learn to imagine future states directly from camera pixels, then plan through that imagined space. There is something almost poetic about the idea: a robot that dreams ahead, that lives out possible futures in a compressed mental theatre before lifting a single finger. But the poetry has run into a hard mathematical wall. For tasks that stretch across many steps — picking up a cup, opening a drawer, navigating a maze — the predictions drift and errors compound like a whispered rumor passed down a long chain of dinner guests, each adding their own distortion until the original message is unrecognizable. Single-level imagination simply runs out of breath.
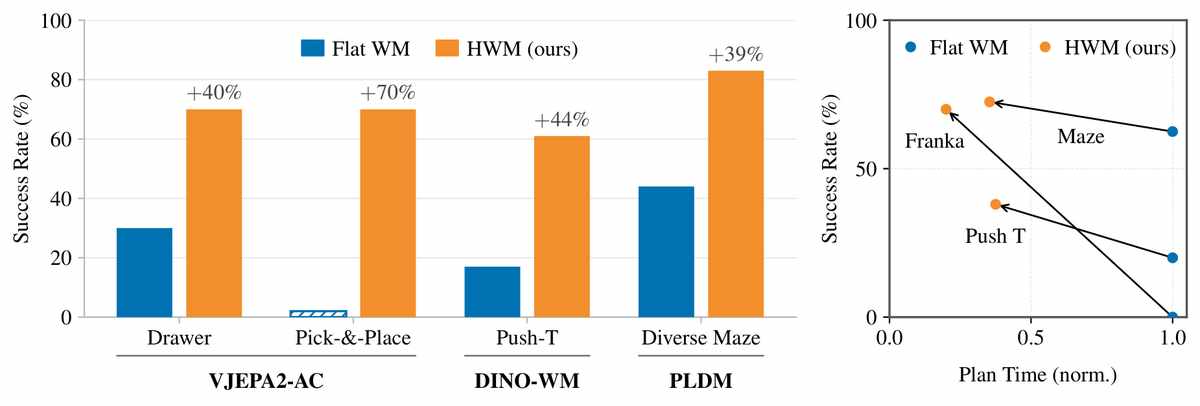
A team led by Nicolas Ballas at FAIR at Meta has now made a compelling attempt to teach robots to think in chapters. Their preprint (arXiv:2604.03208) introduces Hierarchical Planning with Latent World Models, or HWM — an architecture that learns to plan at multiple temporal scales within a shared representational space, compressing long action sequences into meaningful chunks and using the distant future as a beacon for the immediate next move. The result, in the most concrete terms, is this: on a real-world Franka robotic arm performing pick-and-place tasks guided only by a goal image, hierarchical planning succeeds 70% of the time. Without hierarchy, the same planner fails completely.
To understand what that zero percent means, we need to step into the robot's mind — or rather, into the latent space where its planning unfolds. A latent world model is a neural network trained to compress high-dimensional sensory input (like a video feed) into a low-dimensional code, then predict how that code will evolve as the robot acts. Once trained, the model can be used for planning: the robot imagines a sequence of actions, unrolls the predicted latent states, and checks whether the final state matches a given goal. This is model predictive control in the dark, guided by nothing but internal consistency. The beauty — and the fragility — of this framework is that the model is trained purely on next-latent prediction, never on task-specific rewards. It learns to anticipate, not to evaluate.
The fragility is what the Ballas team confronts. For a pick-and-place task requiring perhaps twenty primitive motor commands — move down, close gripper, lift, swing, lower, open — the prediction errors from each imagined step amplify geometrically. By the time the planner reaches the end of the sequence, the latent state it anticipates bears as much resemblance to reality as a game of telephone does to the original phrase. The search tree, meanwhile, branches combinatorially with the planning horizon. Even with clever sampling-based methods like cross-entropy minimization, the planner simply gets lost in its own imagination.
HWM’s solution is disarmingly elegant: instead of one world model, learn two. A long-horizon model predicts latent states at a coarser timescale, skipping over the micro-details. A short-horizon model works at the fine grain, predicting the immediate consequences of individual motor commands. The two models share the same latent space — the same mental canvas — so the coarse predictions of the high-level model can be passed down as subgoals for the low-level model to pursue. There are no extra rewards, no task-specific skill libraries, no separate hierarchical policy networks. Just a conversation between two versions of the same imagination, one zoomed out, one focused in.
The trick that makes this computationally feasible is the action encoder: a neural network that compresses a chunk of, say, ten primitive actions into a single latent macro-action. The high-level planner searches not through the vast space of individual motor torques but through a compact codebook of meaningful sequences. This is not a hack; it’s a recognition that most useful behaviors in the world are compressible. A “pick up the cup” motion might involve hundreds of joint torques, but it can be summarized in a handful of latent coordinates. The macro-action space is the storyboard; the primitive actions are the individual frames.
When the hierarchical planner runs, it functions in a closed loop, replanning continuously as new observations arrive. The high-level model unrolls a sequence of macro-actions to reach the goal, and the first predicted latent state of that unroll becomes the subgoal for the low-level model. The low-level planner then searches for primitive actions that bring the robot to that subgoal within the next few timesteps. This dance repeats: high-level strategist whispers a target, low-level tactician lunges toward it, the world provides feedback, and the cycle begins again. There is something almost conversational about the architecture, a turn-taking between abstraction and execution.
A two-level planner using macro-actions and subgoals solves difficult long-horizon tasks more reliably. It matches or exceeds standard planning while using roughly one-third the time. (Source: arXiv:2604.03208)
The real-world results are striking. On a Franka arm with a dual gripper, HWM solves pick-and-place tasks from a single goal image with 70% success — a task where the single-level planner achieves zero. On drawer manipulation, the gap is equally stark. In simulated environments like Push-T and diverse maze navigation, the hierarchical planner consistently outperforms its flat counterpart while using up to three times less planning compute. The maze results are particularly illuminating: the high-level planner generates pink trajectories that dart toward corridor junctions, while the single-level planner’s teal paths wander and stall, unable to see past the next bend.
| Method | Manual Subgoals | End-to-End |
|---|---|---|
| VJEPA2-AC | 80%/80% | 0%/0% |
| VJEPA2-AC (hierarchy) | 80%/80% | 70%/60% |
A hierarchical planner automatically recovers over 75% of the success rate of a manually guided robot task. This shows robots can learn complex sequences from just a goal image, without requiring step-by-step human instructions. (Source: arXiv:2604.03208)
A subtle finding, buried in the team’s ablation studies, is that the dimensionality of the macro-action matters enormously. If the macro-action latent space is too small — a capacity bottleneck — the high-level planner cannot express a useful plan, and success plummets. If it is too large, the subgoals become unreachable for the low-level planner; the cosine similarity between the inferred primitive actions and expert behavior drops. There is a sweet spot: a moderate latent dimensionality that biases the high-level model toward greedy, reachable subgoals. It’s a striking demonstration that abstraction is not just about compression but about finding the right level of detail — a Goldilocks principle for mental models.
All of this, however, comes with important caveats — and the dialectical honesty of science demands we examine them closely. The paper frames its approach as “zero-shot” planning, meaning planning in new scenarios without additional task-specific training. But an important question raised by earlier work on zero-shot world models (Zhou et al., DINO-WM) is whether the term fully applies here. The high-level world model and the action encoder both require additional training data beyond the base world model. The robot does not need task-specific rewards or demonstrations for each new task, but it does need a general-purpose training phase in which it learns to predict at multiple scales. Calling this zero-shot in an unqualified sense is, at best, imprecise. The planner’s ability to generalize is real, but the path to that generality is paved with prior experience.
A deeper methodological question arises from the design of the experiments. The hierarchical planner combines three innovations: temporal abstraction (a separate high-level model), action compression (the macro-action encoder), and the hierarchical decomposition itself. The ablation studies in the paper vary macro-action dimensionality, which simultaneously changes the capacity of the action encoder and the structure of the high-level planning space — making it difficult to attribute performance changes to a single factor. It is therefore difficult to know, from the published evidence, whether the performance gains derive from the hierarchical structure or simply from the ability to plan with compressed actions. A natural question is: what would happen if you gave a flat planner access to the same macro-actions — reducing the search space without introducing a two-level hierarchy? If a single-level planner equipped with compressed actions could achieve comparable results, then the hierarchy is interesting but not essential — a narrative convenience rather than an architectural necessity.
This is not a dismissal. The work sits in an interesting tension with the flat-world-model planning literature, where some studies have shown that careful tuning of the planning algorithm can itself overcome horizon limitations — though whether that holds for the non-greedy, multi-stage tasks studied here remains an open question. The HWM results suggest that for truly long horizons, algorithmic tuning alone may not suffice — that structural decomposition is required. But the case is not yet airtight. The paper opens a conversation rather than closing one.
Perhaps that is the most honest way to see it: a promising architectural sketch, complete with the rough edges and unresolved questions that mark genuine research rather than press-release triumphalism. The robot that plans in chapters is learning something real, but we are only beginning to understand what it learns and how.
There is a deeper story here, one that transcends the specific engineering of pick-and-place success rates. For decades, the dream of artificial intelligence has been haunted by a particular failure mode: the agent that can handle the present but cannot bind moments together into a coherent arc of intention. A language model that produces locally fluent sentences but drifts in topic. A game-playing agent that masters tactics but lacks strategy. A robot that can grasp a cup but cannot put it across the room. Hierarchical planning with learned world models is one step toward binding the moments, toward giving an agent a narrative thread.
Think of what it means for a purely predictive model — a neural network trained on nothing more than “given this sensory input and this action, what happens next?” — to spontaneously organize its internal representations into chapters. There are no labels telling it which latent states are subgoals. There are no external rewards carving the continuous stream of experience into meaningful segments. The structure emerges from the architecture itself, from the need to plan efficiently under computational constraints. This is, in a quiet but profound sense, a rudimentary form of synthetic phenomenology — a machine whose inner world acquires a temporal grain because that grain is instrumentally useful.
The robot is not conscious, of course. But the mechanism bears an uncanny resemblance to how human cognition processes extended action sequences. We do not plan a cross-country drive as a 2000-mile sequence of precise steering angles; we break it into segments — get to the highway, pass through the city, stop for gas — each segment a semantic chunk that organizes the motion. The HWM architecture doesn’t plan highway exits, but it does plan pick-up placements and drawer interactions. The computational logic is the same: abstraction as compression, hierarchy as the natural structure of long-range intention.
The road ahead is clear, even if the exact timeline is not. The Ballas team has shown that hierarchical latent planning can work on real hardware. The next steps — isolating the sources of gain, tightening the zero-shot claims, comparing against compressed flat baselines — are the necessary, unglamorous work of turning a promising demonstration into a solid scientific contribution. That work will be done, because the questions it raises are too interesting to leave unanswered.
And at the far end of the trajectory, beyond the immediate benchmarks and the success-rate tables, lies a vision that is both ambitious and unsettling: agents that learn not just to plan, but to organize their own experience into a hierarchy of narratives, to build for themselves a world that makes sense at multiple scales simultaneously. When we finally see a robot that can clean a messy room, cook a meal, or assemble a piece of furniture — tasks that require tens of thousands of coordinated movements over minutes or hours — it will not be because we programmed every step. It will be because the robot learned to dream in chapters.
Perhaps, then, the real significance of HWM is not the 70% success rate or the 3x compute reduction. It's that we are watching, in real time, the emergence of a new kind of computation — one where the mind of the machine is not a monolithic simulator but a parliament of sub-minds, each with its own temporal horizon, negotiating a shared future. The robot’s latent space is becoming a stage, and on that stage, subgoals flicker into being like characters in a play that is only just beginning to be written.
References
- Wancong Zhang et al., Hierarchical Planning with Latent World Models, arXiv:2604.03208
- Zhou et al., DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning, arXiv:2411.04983
- Sobal et al., Learning from Reward-Free Offline Data: A Case for Planning with Latent Dynamics Models, arXiv:2502.14819
- Terver et al., What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?, arXiv:2512.24497